植物基因组蛋白质序列的制备
本文总阅读量 次
一般情况下,植物基因组 DNA 序列及注释文件可以在 ensembl 网站直接下载到,但蛋白质序列貌似不是很好下载,各处下载的序列文件格式、ID 等都有很大的不同,NCBI 上的也比较杂乱,所以还是自己翻译为好,这里依旧使用 TBtools。
数据下载
其实在 ensembl 网站 可以下载到 DNA 序列、蛋白质序列及注释文件,但蛋白质序列的 ID 格式比较乱

我比较喜欢由 ID 直接对应序列的
先从 ensembl 网站 下载 DNA 序列及注释文件
打开 ensembl 网站 后,直接在首页的物种列表里选择物种,我们课题组主要做水稻,我就以水稻为例

点击物种详情页的 Download DNA sequence 就会跳转到 DNA 序列的 ftp 页面
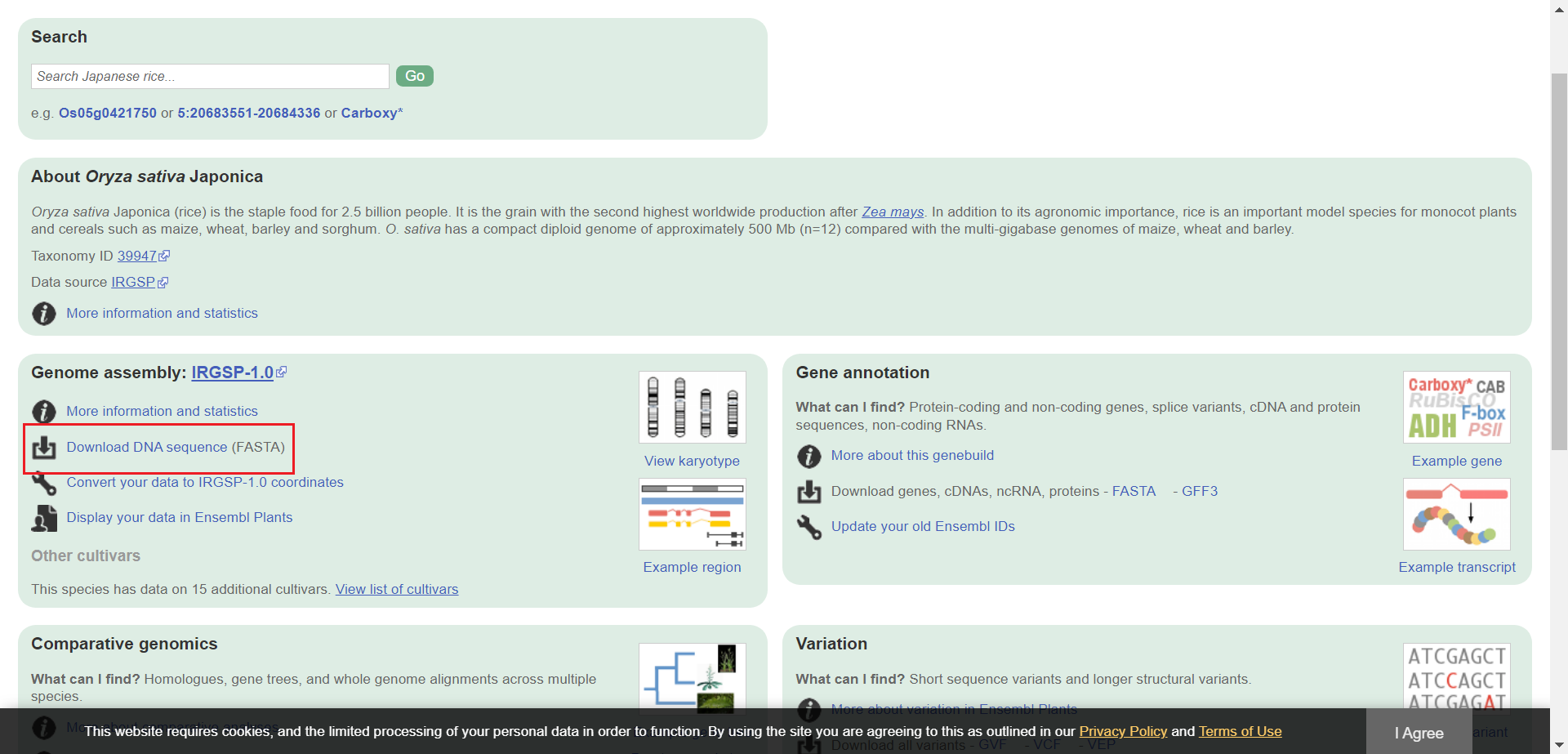
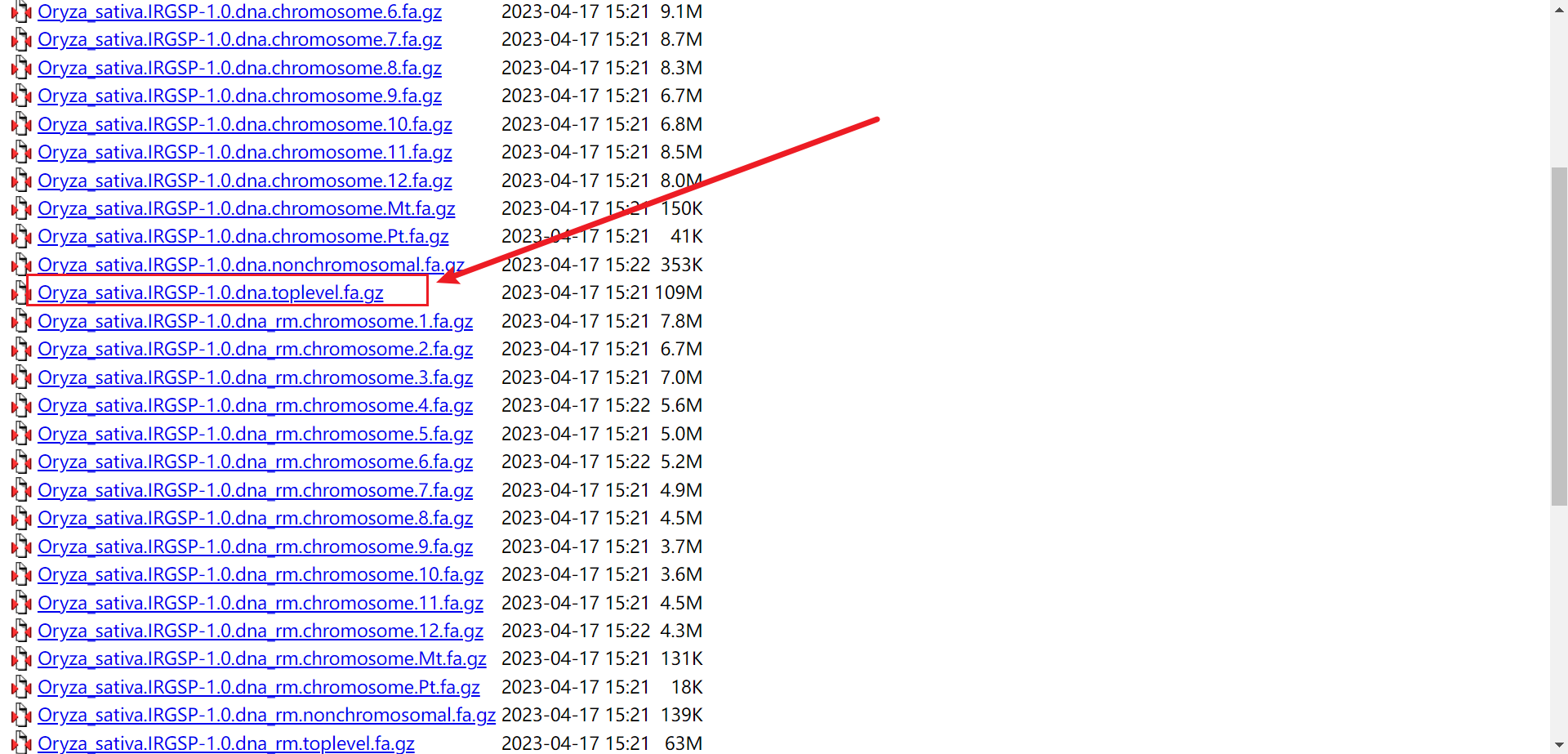
以 dna.toplevel 结尾的就是基因组的全部 DNA 序列,其他的是各条染色体上的基因的 DNA 序列
回到详情页,点击 Gene annotation 下的 GFF3 下载注释文件
下载整个基因组的注释文件,而不是各条染色体的

再回到详情页,点击 Gene annotation 下的 FASTA

跳转到 ftp 页面之后我们可以看到这里有 DNA、ncrna、cDNA、CDS 及蛋白质(pep)
打开 pep 文件夹下载所有蛋白质序列

但这个蛋白质序列的 ID 很长,所以我们自己制备蛋白质序列
蛋白质序列制备
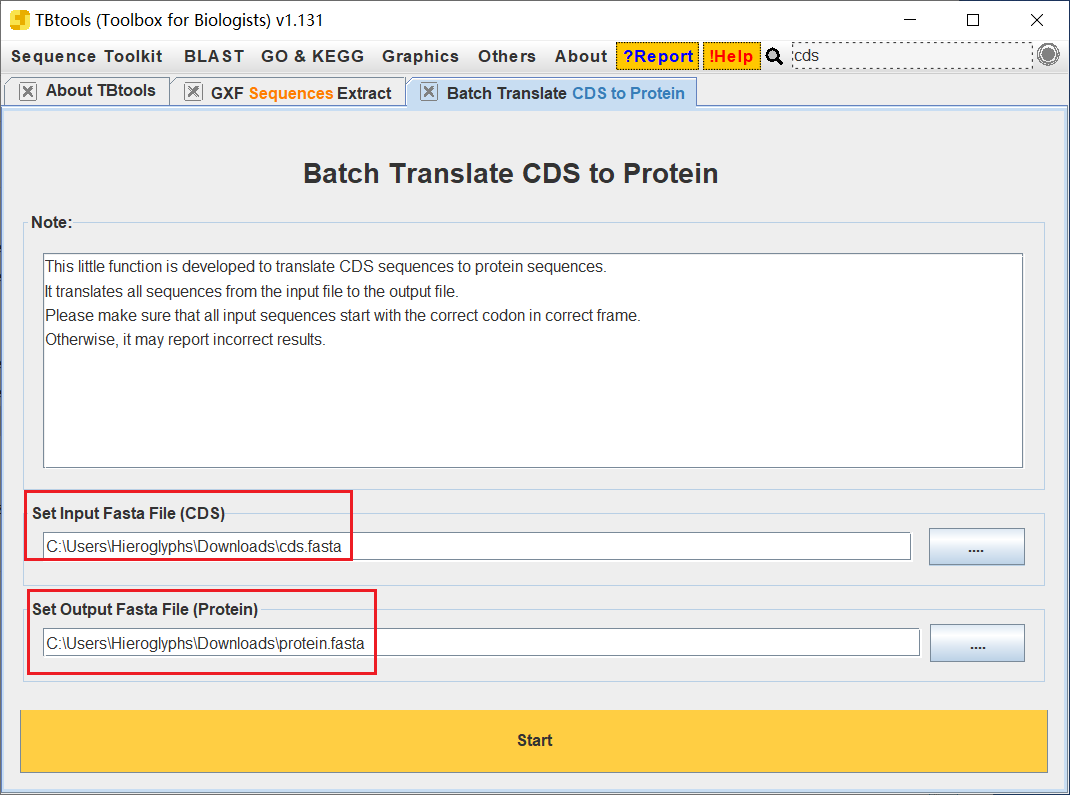
打开 TBtools 的 GTF Sequences Extract 工具,导入注释文件和 DNA 序列
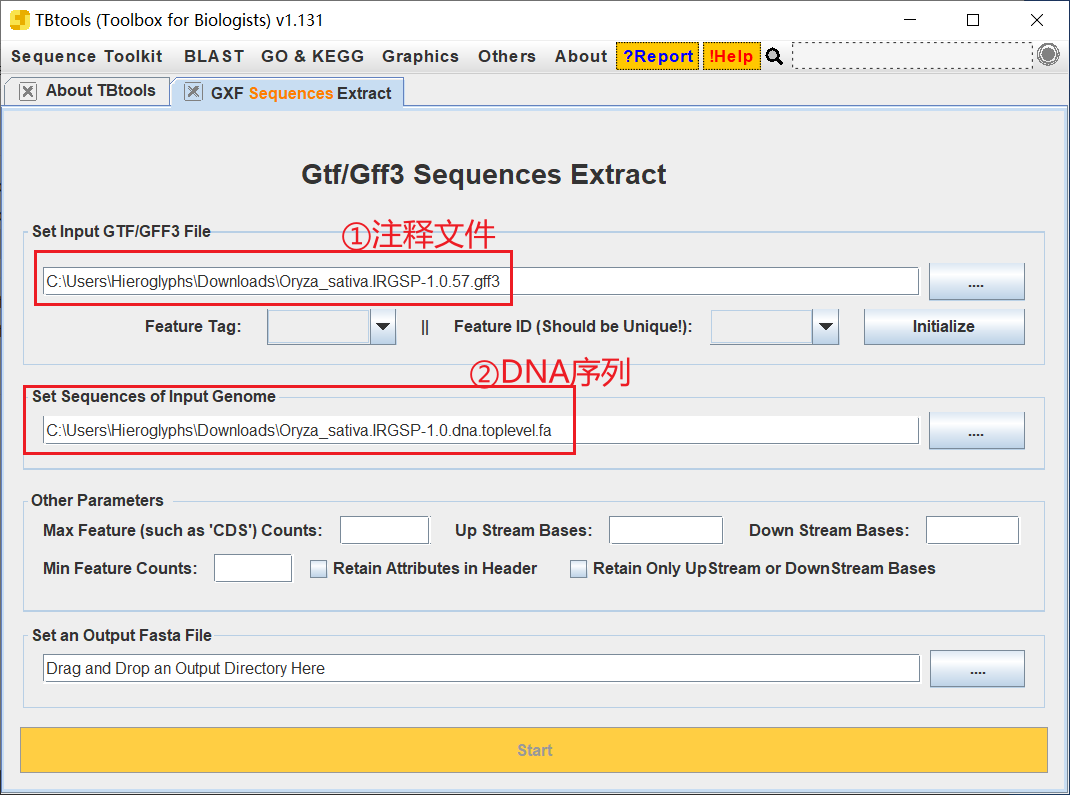
点击 Initalize 进行初始化,然后会弹出一个弹窗,关掉即可,Feature Tag 选择 CDS,Feature ID 选择 Parent,设置好输出文件后开始
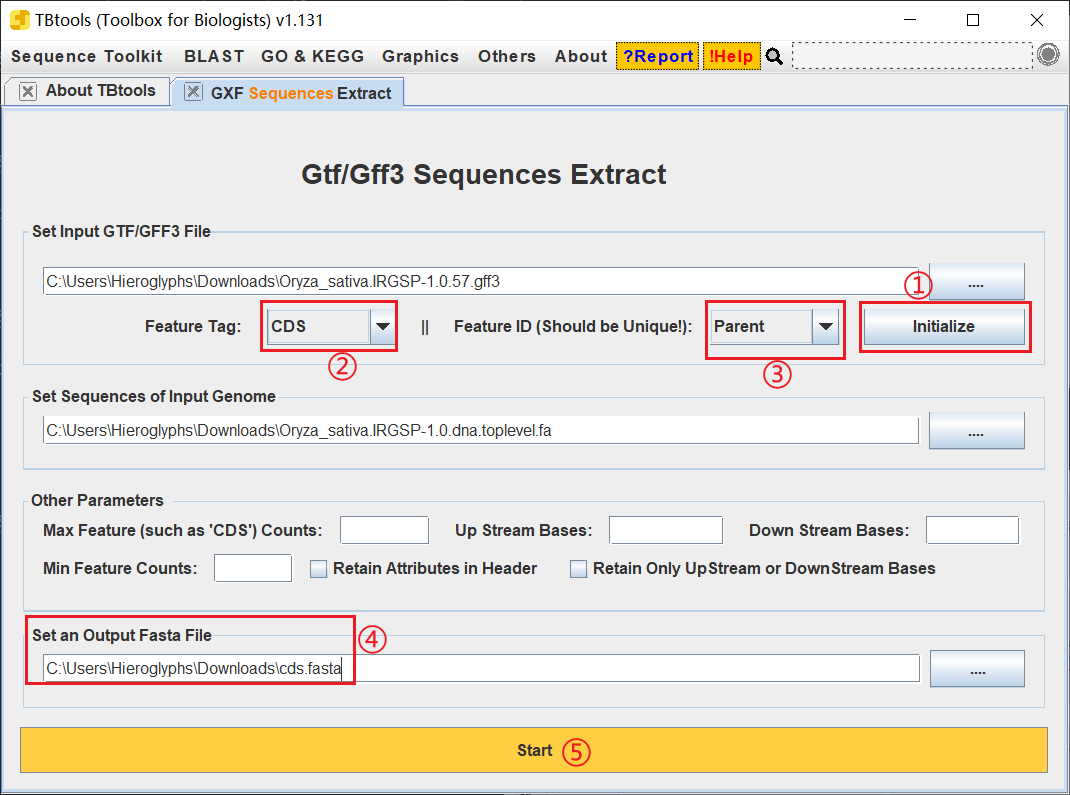
这里我们是为了提取 CDS 序列,为什么不直接下载呢?还是 ID 的原因。.. 下图可以自己看看

顺便解释一下这里选择标签的理由
初始化之后弹出的弹窗,事实上用户辅助用户选择 Feature Tag 和 Feature ID
Feature Tag,一般是 CDS, Exon, mRNA, Transcript, Gene 等,用户往往已经知道自己要提取什么,不需要辅助
Feature ID,以 CDS 和 mRNA 为例,我们很清楚,真核生物中,大多数基因均是断裂基因,即 Exon-Intron-Exon… CDS 即 Exon 的部分,所以 CDS 本身在基因序列的尺度上,也是被 Intron 所分隔,当我们需要提取 CDS 的时候,往往我们说的并不是提取 一截 CDS,而是把某个转录本对应的几截甚至几十截 CDS 按照正确的顺序和方向连接起来之后的真实的 CDS 全长
GFF3 注释文件中,同一个转录本拥有几截 CDS,这些 CDS 可以以 Parent 这个 Feature ID 来归组,并组合成的 CDS 全长,事实上,这个文件比较简单,因为 CDS 并没有更多的 Feature ID 可以选择,在其他物种中,常常会出现各种各种的 Feature ID,比如直接是 ID=
可以看到图片中还有 mRNA,在这个注释文件中,每一个 mRNA 基友 ID= 也有 Parent=,前者事实上是这个 mRNA 独有的标签,后者则记录了这个 mRNA 属于是哪一个基因的转录本之一,此时,如果是要提取这个 mRNA 的序列【包括 Exon 和 Intron】,那么设置 Feature ID 为 ID 则是正确的,如果选择 Feature ID 为 Parent,则只会得到不理想的结果,一个基因多个转录本会有完全相同的 Parent 便签,这些转录本会按顺序串联起来,这并不没有生物学意义
等待一会提取完成后,我们先对提取的 CDS 序列文件进行一些处理
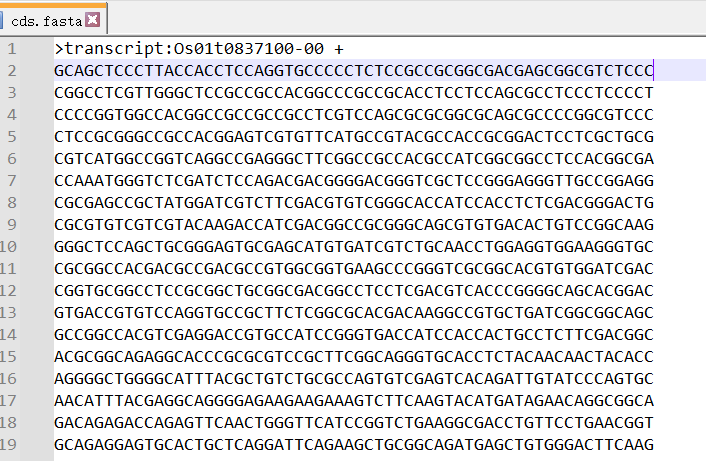
可以看到其实序列对应的 ID 已经很简单了,但是还是有些不需要的,比如 transcript: 和后面的+ - ,使用 Notepad++或记事本之类的编辑器,全部替换为空

现在就是最后一步了,使用 TBtools 的 Batch Translate CDS to Protein 工具把 CDS 翻译成蛋白质序列