GO&KEGG 富集分析
本文总阅读量 次
功能富集分析是将基因或者蛋白列表分成多个部分,即将一堆基因进行分类,而这里的分类标准往往是按照基因的功能来限定的。换句话说,就是把一个基因列表中,具有相似功能的基因放到一起,并和生物学表型关联起来。
何为 GO 和 KEGG?
为了解决将基因按照功能进行分类的问题,科学家们开发了很多基因功能注释数据库。这其中比较有名的一个就是 Gene Ontology(基因本体论,GO)和 Kyoto Encyclopedia of Genes and Genomes(京都基因与基因组百科全书,KEGG)。
其中,GO 是基因本体论联合会建立的一个数据库,旨在建立一个适用于各种物种的、对基因和蛋白功能进行限定和描述的,并能随着研究不断深入而更新的语义词汇标准。GO 注释分为三大类,分别是:分子生物学功能(Molecular Function,MF)、生物学过程(Biological Process,BP)和细胞学组分(Cellular Components,CC),通过这三个功能大类,对一个基因的功能进行多方面的限定和描述。
而 KEGG,大多数听说过 KEGG 的人都会把它当做一个基因通路(Pathway)的数据库,其实人家的功能远不止于此。KEGG 是一个整合了基因组、化学和系统功能信息的综合数据库。KEGG 下属 4 个大类和 17 和子数据库,而其中有一个数据库叫做 KEGG Pathway,专门存储不同物种中基因通路的信息,也是用的最多的一个,所以,久而久之,KEGG 就被大家当做是一个通路数据库了
如何做功能富集分析?
功能富集分析的算法有很多种,能够做功能富集分析的工具也非常多,如果大家想深入了解的话,下面是一个工具列表可供大家学习。
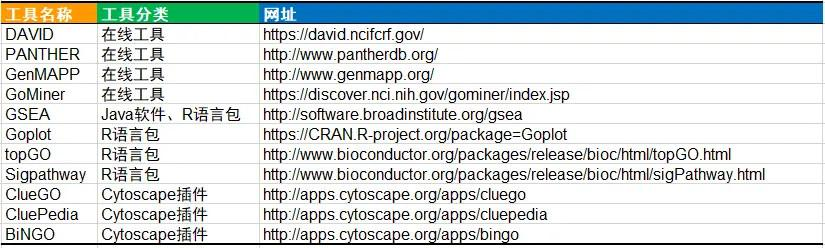
在以上所有的工具中,有一个工具是最为常用,也最为权威,那就是 DAVID,DAVID 是由美国 Leidos 生物医学研究公司的 LHRI 团队开发的一个在线基因注释及功能富集网站,其网址为 https://david.ncifcrf.gov 为什么说 DAVID 它是最权威的呢?看下图就知道了:仅 DAVID 这一个软件就发表了 10 篇 sci 文章,其中 5 分以上 7 篇,累计影响因子将近 85 分。其他用 DAVID 进行分析并发表的文章就更不计其数了

获取富集数据
打开 DAVID 官网:https://david.ncifcrf.gov/
点击上方功能菜单 Functional Annotation
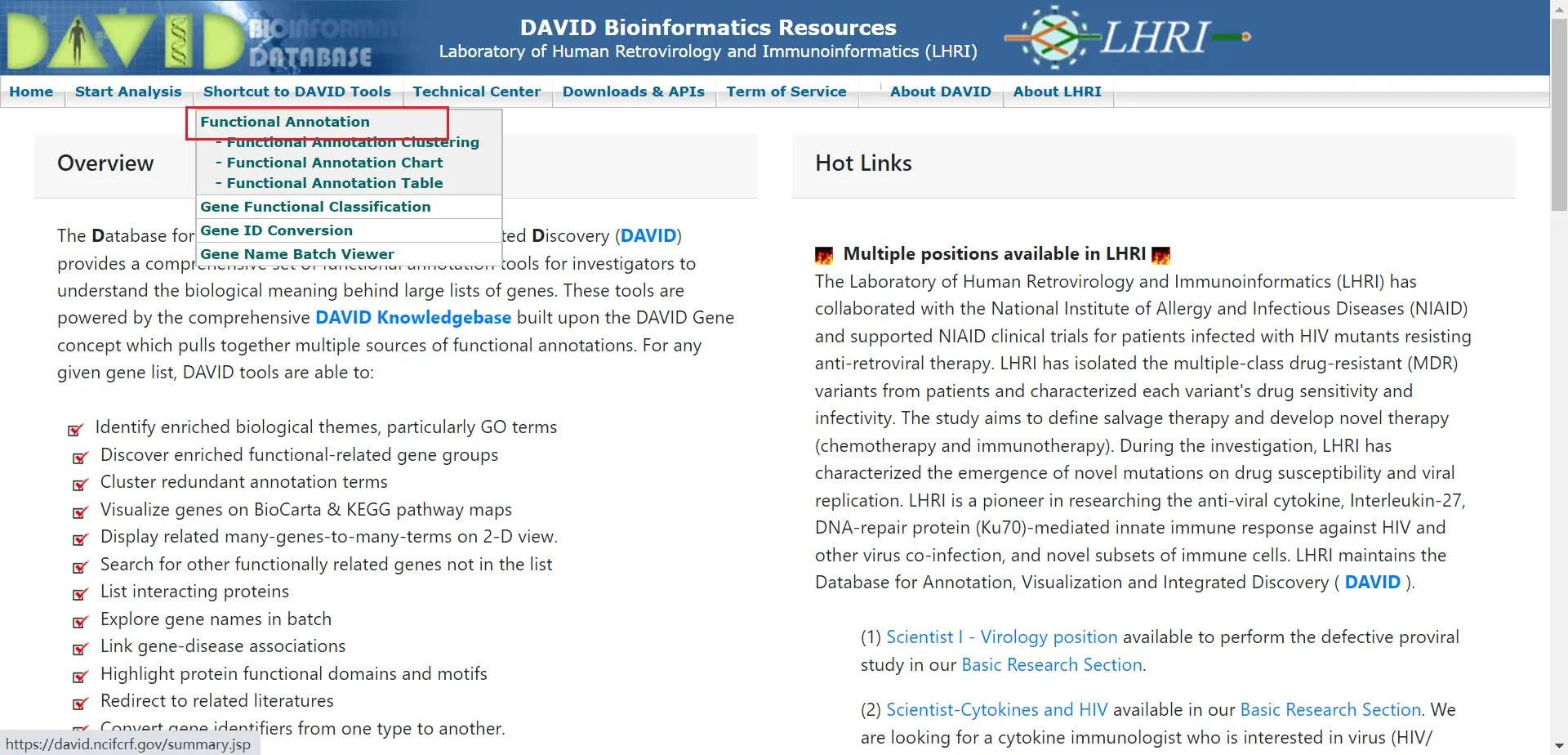
选择上方的 upload 选项卡,在编辑框内粘贴基因 ID 列表,选 ID 类型为 ENSEMBL_GENE_ID ,选择列表类型为基因列表,最后上传列表

现在展示出的即富集分析结果,取消勾选上方 Check Defaults 取消全选,展开 Gene_Ontology 项,勾选 BP、CC、MF 项,点击最下方 Functional Annotation Chart 将勾选的项目以列表形式给出

随后就会跳出一个浏览器页面,以列表的形式将上述结果展示给我们了,点击右上方 Doanload File 将新弹出窗口中的数据复制保存在 Excel 表格中,按顺序保留下列数据
BP、CC、MF
此处我解释一下 BP、CC、MF 项分别为什么意思
GO 是 Gene Ontology 的缩写,是一种用于生物信息学和计算生物学中的术语表达的标准格式。GO 主要由三个部分组成:分子功能(Molecular Function,MF)、生物过程(Biological Process,BP)和细胞组分(Cellular Component,CC)这些术语描述了基因和蛋白质的不同功能和所处的环境
BP(Biological Process)是指分析对象(如基因)所参与的生物学过程,通常是一组相互作用的生物学事件,这些生物学事件在时间和空间上有一定的结构和组织,比如细胞代谢、信号转导、生物合成等等
CC(Cellular Component)是指分析对象(如蛋白质)所在的细胞组成部分,即它所在的细胞器、细胞构造和細胞組織中对应的位置。比如细胞膜、线粒体、细胞核等等
MF(Molecular Function)是指分析对象(如基因或蛋白质)具有的分子功能,即它所扮演的特定化学活性,比如催化反应、配体结合、蛋白质结合、转录因子结合等
处理数据
第一列:富集的名字(Term) 第二列:是 X 轴显示内容,例如 gene ratio 等(%列) 第三列:p 值或者 fdr,即图中的颜色,根据 p 值变化(p-value 列) 第四列:基因数,控制气泡大小(Count) 第五列:为可选列,为分类信息,例如 BP,CC,MF 等(Category)
在制作气泡图时,通常会对富集分析结果中的 P 值进行转换,以避免图像上 P 值的差异过分压缩的情况。常用的转换方式是将 P 值进行-log10(以对数值)的处理

对数据进行整理,简化一下名称,最终得到如下数据

绘图
打开微生信平台(http://www.bioinformatics.com.cn/)的富集气泡图功能进行绘图,也可以使用 R 和 Excel,R 的环境比较复杂,这里我就不放代码了。

结果分析
在这个 GO 富集分析结果中,我们可以从不同的角度来分析:
在功能方面(GOTERM_MF_DIRECT),我们可以看到,13 个基因处于“半胱氨酸型内切酶抑制剂活性”的功能位置,这一结果的贡献值(P 值,Bonferroni、Benjamin 人为误判率)非常小,表明这 13 个基因的相似分布可能不是随机事件造成的,进而推断这些基因在相关的生物过程、疾病或免疫应答方面扮演着重要的作用
在细胞组分方面(GOTERM_CC_DIRECT),这 13 个基因中有 11 个基因分布于“细胞外区域”,并具有非常高的显著水平和 FDR 调整系数值,表明这些基因在“细胞外区域”方面的富集并不是随机发生的,这表明这些基因可能参与了水稻的细胞外相关生理作用和功能
在生物过程方面(GOTERM_BP_DIRECT),这 13 个基因中的所有基因均涉及到“防御反应”,且 P 值和调整后的 P 值均非常小,这表明这些基因在水稻防御反应中可能扮演一个重要的角色
因此,结合这些结果,这些基因群应该与防御反应有关,它们在水稻中可能扮演着一种重要的保护性功能